Abstract
When you look for a NoSQL data store for your service, there are a number of choices. However, if your selection criteria are not simple, you find very few options, and you may even need to develop features to cover the gaps in the database. For a collection of services that we were developing, we needed a key-value store and a document store with high availability, high read performance, and high write performance. Some of the use cases needed this data store to be the system of record, needing point-in-time restore capability. We also needed “read-your-own-write” consistency for some of the operations. This blog is about how we came to use Couchbase 3.1 and how we addressed the gaps that were found.
Couchbase setup
In our setup, there are three Couchbase clusters, one each in a data center, forming a cluster set. Each cluster has the full data set and has bidirectional Cross Datacenter Replication (XDCR) set up with each of the other two clusters in the cluster set. Each cluster has a replication factor of 2, that is, there are six copies of a document in the cluster set. The services read from and write to the primary node local to it. If the call to primary fails, the application uses its secondary node. This setup gives a highly available and eventually consistent distributed data store.

Improvements
Availability
Though the above setup gives high availability, one issue with the above setup is that when an entire cluster is down or a node is slow performing, there is no way for the application to detect and switch to another cluster or a better performing node.
If the application is aware of all nodes in the cluster set and can choose the best performing node, availability improves and the service-level agreement (SLA) is more easily achieved. For this, a performance score, which is a weighted average of the query response time for that node, is assigned to the node and stored in a map. We assign more weight (say 90) to the existing score and less (say 10) to the new scores. With this strategy, scores change slowly, small spikes do not affect cluster selection, while large or sustained spikes cause a different cluster to be selected. The application chooses the best performing cluster set and optimal node (primary vs replica) at any given time. This allows for the application to automatically switch when there are external factors, such as prolonged network issues or Couchbase version upgrades.
Validation
The chart below shows the performance during a manually simulated outage scenario. Each window represents a Couchbase cluster that is in a geographically different location. The application that is driving traffic is in the same geographic location as the upper left window.

As the Couchbase cluster with the traffic is taken out with a vicious shutdown -r now across all the nodes, you can see the traffic in the upper left window take a dive, while it picks up a different data center shown in the upper right window.

As the application continues to request data from Couchbase, it occasionally shifts traffic to the third data center, shown as spikes in the lower left window. This is because the application is constantly evaluating the “best” performing cluster and shunting traffic to it.
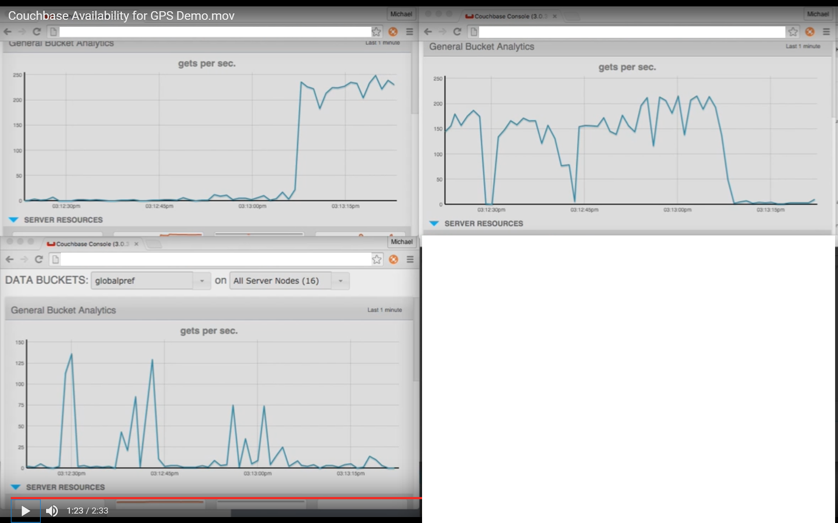
Once the nodes in the “down” cluster finish rebooting and reform the cluster, the application can detect the cluster with trial queries and cause the traffic to shift back to it.
Consistency
A single Couchbase cluster is highly consistent. Given a single key, reads and writes are always to the same primary node and are immediately consistent. The trade-off that Couchbase offers is write availability.
In a multiple-cluster setup, Couchbase sacrifices its strong consistency but gains much better availability. In the event that one node goes down, data for that node can’t be written in the affected cluster; however, you can choose to write to other clusters and rely on the XDCR setup to bring all your clusters back into consistency.
Even though the multiple-cluster Couchbase was meant to be eventually consistent, some of our operations needed high (“read your own write”) consistency.
High-consistency API
There are many ways to impose a higher consistency than what the underlying storage technology provides. In the data write-read cycle, there are three options on which phase can be modified to increase consistency. Additional process can be imposed on the read phase, the write phase, or both phases.
Read-phase consistency
With no guarantees during the write phase, we can increase the consistency in the read phase by simply always reading data from all the clusters and either picking the latest or picking the value that has a quorum.
Unfortunately, this does not guarantee “read your own write” consistency. When a value is updated, until the updated value is propagated to a quorum of nodes, the value returned is always the old value, unless “pick latest” is used. If the node that has the latest data is down, “pick latest” won’t work.
Write-phase consistency
We can enforce strong consistency in the write phase by making sure that the data is consistent before we return success on write. There are many ways to do this.
- Multi-write. The application can write to all the clusters all the time and wait until the writes all return successfully before returning a success to the caller. This does make the reads very fast and efficient. The complexity of the solution greatly increases when a node is down or the network is partitioned or multiple threads are attempting to update the same key.
- Read-back. The application can take advantage of XDCR by writing to the local cluster and performing reads to all clusters until all the reads fetch the value written. Once XDCR completes the transfer of documents and the correct values are fetched, the write operation can finally succeed. This solution also suffers from the same complexity increases for down nodes, partitioned network, or race conditions.
Both of techniques focusing on this phase improve consistency most of the time and allow us to perform high-performance local reads most of the time, but it is too complex if we have to guarantee “read your own write” capability during node failures or when the network is partitioned.
Both-phase consistency
A popular approach in both-phase consistency requires quorums during both phases. Obtain a majority quorum upon write, and during the read phase obtain another quorum. We can mathematically choose the consensus threshold in each the read and write quorums to guarantee “read your own write” consistency.
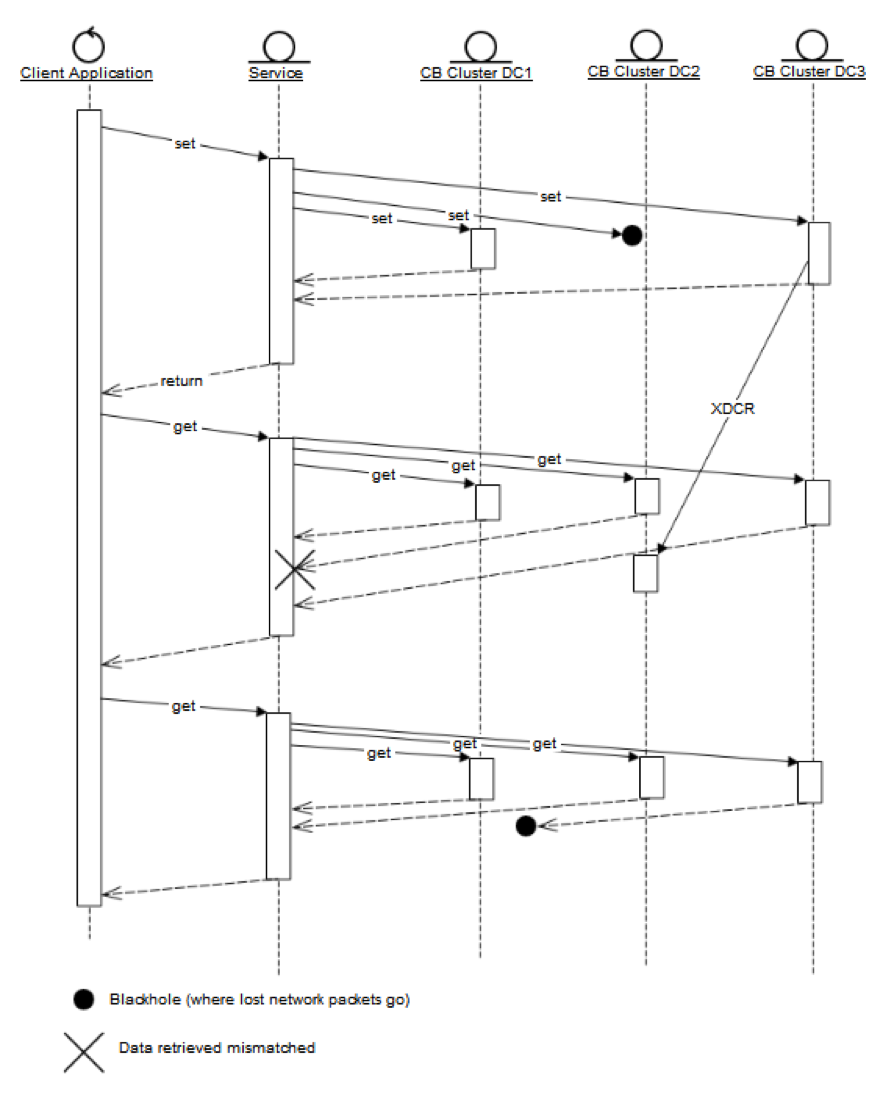
This communication diagram shows how expensive get and set calls are when we want to guarantee “read your own write” consistency. Every call requires network communication with every cluster that has the information. And as the number of clusters grows, the overhead with this approach can grow.
It is best to provide this only to the use cases that absolutely need this.
Monitoring XDCR lag
Discovering the data lag due to XDCR can give us the ability to make informed suggestions to our clients on when to actually use the very expensive “read your own write” consistency capability. In order for us to accurately measure how long it takes between writing the data and when data is available in the other clusters to be read, we simply generate heartbeats. With every heartbeat, we write the current timestamp to the local cluster and then immediately read the same document out of all the other clusters in parallel. When we take the difference between what timestamp was written, and what timestamp was received, we measure the data latency very accurately. The delta of the timestamp from the data read and the timestamp of when the data arrived can give the absolute staleness of the data from each cluster.
From our measurements we found that the data lag is very close to the network latencies between the various clusters.
Backup and restore
Some of the use cases needed point-in-time backup and restore capability. Couchbase 3.X backup and restore tools were not yet mature, but it provided a Kafka connector to stream changes to Kafka based on DCP. This was used to implement point-in-time backup and restore.
We set up a Kafka cluster to which the changes from one of the Couchbase clusters were written to. From Kafka, the readers can read the changes and write them to an Oracle database table. This table contains the changes to the Couchbase document along with the timestamp of the change. We developed a restore tool that gives the users the ability to select the data and the point in time from which restoration needs to be made. On execution, the tool extracts rows from the table, saves them to a file, and updates one of the Couchbase clusters, which then gets replicated.
In addition to the standard Couchbase keys, application-level keys are stored. This allows us to perform selective restores. If some specific values are corrupted, the corrupted data alone can be restored.
Race conditions
We avoid race conditions where data being restored might be actively updated from the service by leveraging the following approaches:
- Highly selective restore. Rarely would we want to restore everything back to a specific point in time. There is always a time window when the corruption occurs for specific attributes or users. This reduces the data volume and the chance of collision.
- Smaller window of collision. Because the data volume to be restored is small, the duration of the restore process is kept small. The goal is to have the restore complete in minutes rather than hours. In the worst case, where a collision does happen, it is straightforward to identify the documents that collided and run another restore with just the collided documents, so as to roll back the changes performed during the restore that had collisions as “corrupted” data.
Purging logic in the Oracle database
Over time, a lot of data can be collected. To maintain space, we used partition-dropping logic. The data is partitioned in Oracle using the LAST_MODIFIED_TS column modulo 24 months. Every month, the 24th oldest partition is dropped.
Conclusion
NoSQL is great, but it may not be possible to find a product that meets all your needs. Spend the necessary time to evaluate your options. Prioritize your core needs and select the solution that best meets your priorities. Evaluate the gaps, and see if the gaps can be filled in by your application.
A well-chosen NoSQL offering along with the proper application design and implementation can produce a highly available, low-latency, and scalable service to serve your needs.